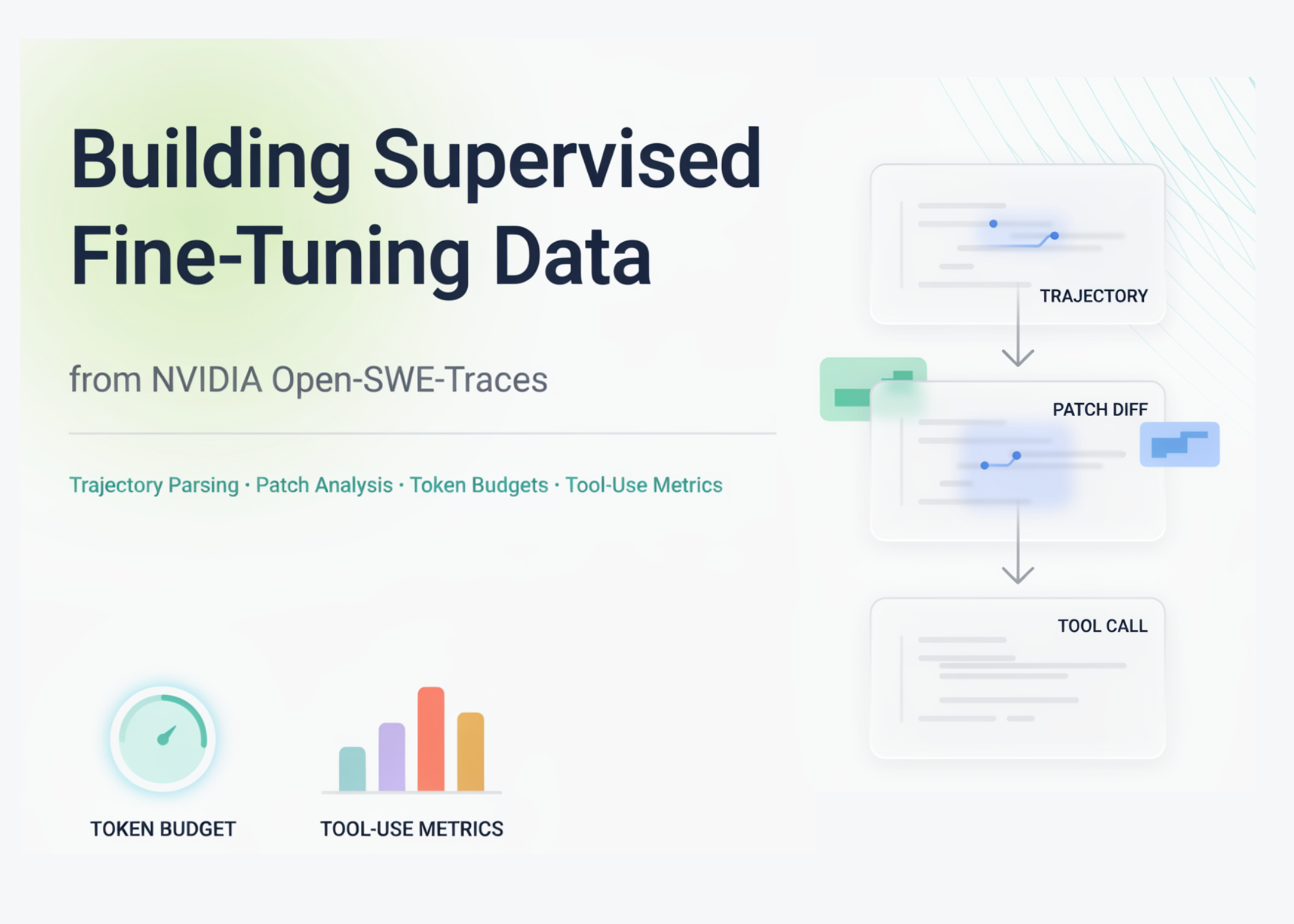
Опубликовано руководство по работе с датасетом Open-SWE-Traces от NVIDIA, предназначенным для дообучения ИИ-агентов в сфере программной инженерии. Методика включает потоковую обработку данных из Hugging Face, нормализацию многоходовых диалогов, извлечение программных патчей и анализ метрик использования инструментов, что позволяет эффективно готовить обучающие выборки для моделей, решающих задачи разработки ПО.
Процесс обработки данных ориентирован на создание качественных обучающих пар для supervised fine-tuning (SFT). Основной акцент сделан на парсинге траекторий действий агента, что позволяет отделить успешные шаги от избыточных операций. Такой подход помогает оптимизировать использование токенов и повысить точность моделей при выполнении реальных инженерных задач, таких как исправление багов или написание кода.
Использование потоковой передачи данных позволяет проводить анализ и подготовку датасетов непосредственно в облачных средах, таких как Google Colab, без необходимости локальной загрузки терабайтов информации. Это значительно ускоряет итерации при разработке специализированных агентных систем, ориентированных на автоматизацию жизненного цикла разработки программного обеспечения.
Ключевые факты
- Датасет Open-SWE-Traces от NVIDIA содержит траектории работы ИИ-агентов, решающих задачи по написанию и исправлению кода.
- Методология включает нормализацию диалогов и анализ эффективности использования инструментов в рамках агентных сессий.
- Реализована возможность потоковой обработки данных из Hugging Face для экономии локальных вычислительных ресурсов.
- Анализ включает расчет токеновых бюджетов и оценку длины траекторий для оптимизации обучения моделей.
- Инструментарий позволяет формировать DataFrame для оценки качества патчей и результативности действий агента.