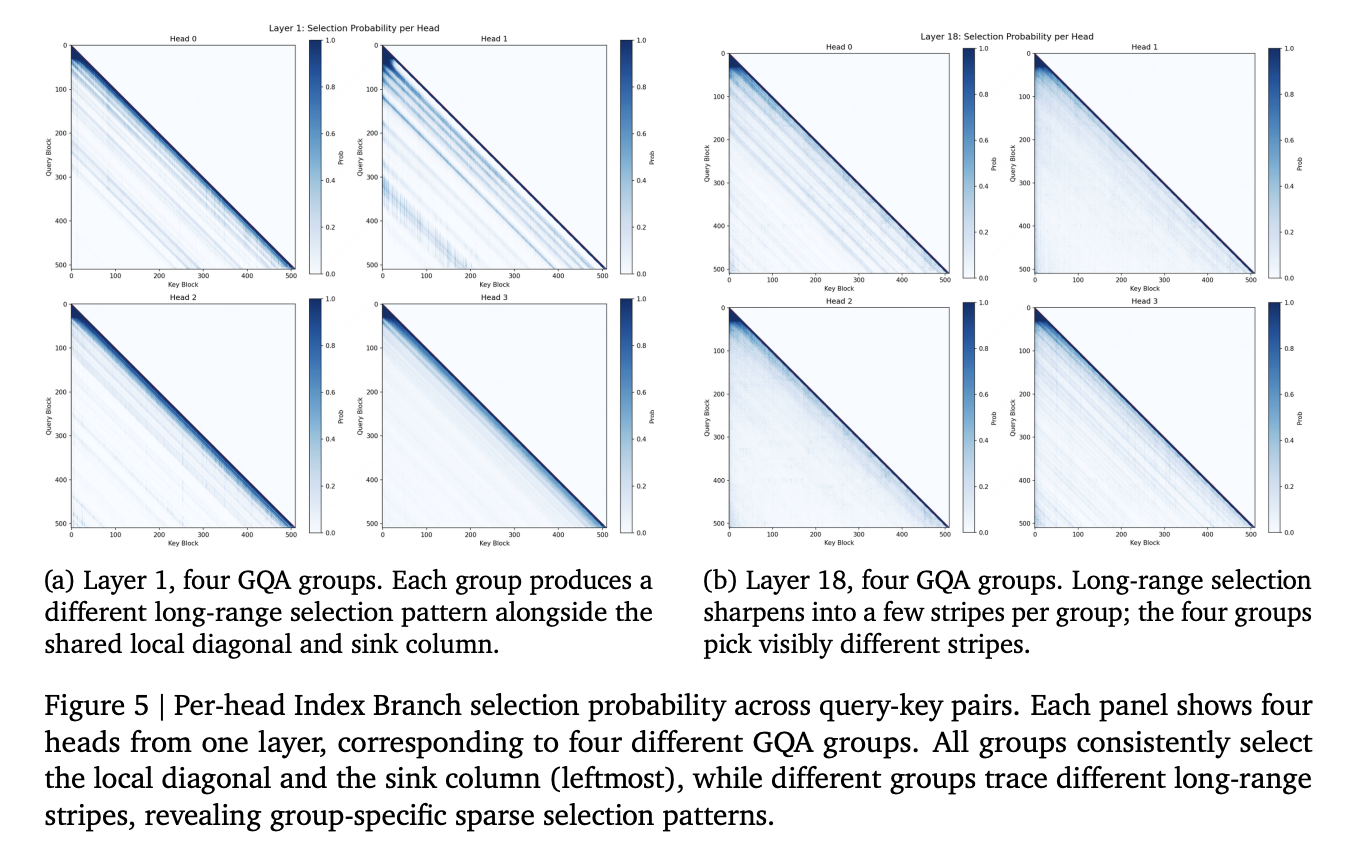
Компания MiniMax анонсировала MSA (MiniMax Sparse Attention) — новый механизм сжатого внимания, основанный на Grouped Query Attention (GQA). MSA использует двухветвую архитектуру: лёгкий Index Branch выбирает Top-k блоков ключ-значение для каждого запроса и группы GQA, а Main Branch обрабатывает только эти блоки.
По словам разработчиков, MSA демонстрирует сопоставимые результаты с GQA на бенчмарках, но снижает вычислительные затраты на внимание на 28,4 раза при контексте в 1 миллион токенов. Модель была обучена на MoE (Mixture of Experts) с 109 миллиардами параметров и бюджетом в 3 триллиона токенов.
MSA может стать важным шагом в оптимизации больших языковых моделей, особенно для задач с длинным контекстом, где вычислительные затраты традиционно высоки. Технология может найти применение в различных ИИ-сервисах, требующих обработки больших объёмов данных с минимальными затратами ресурсов.