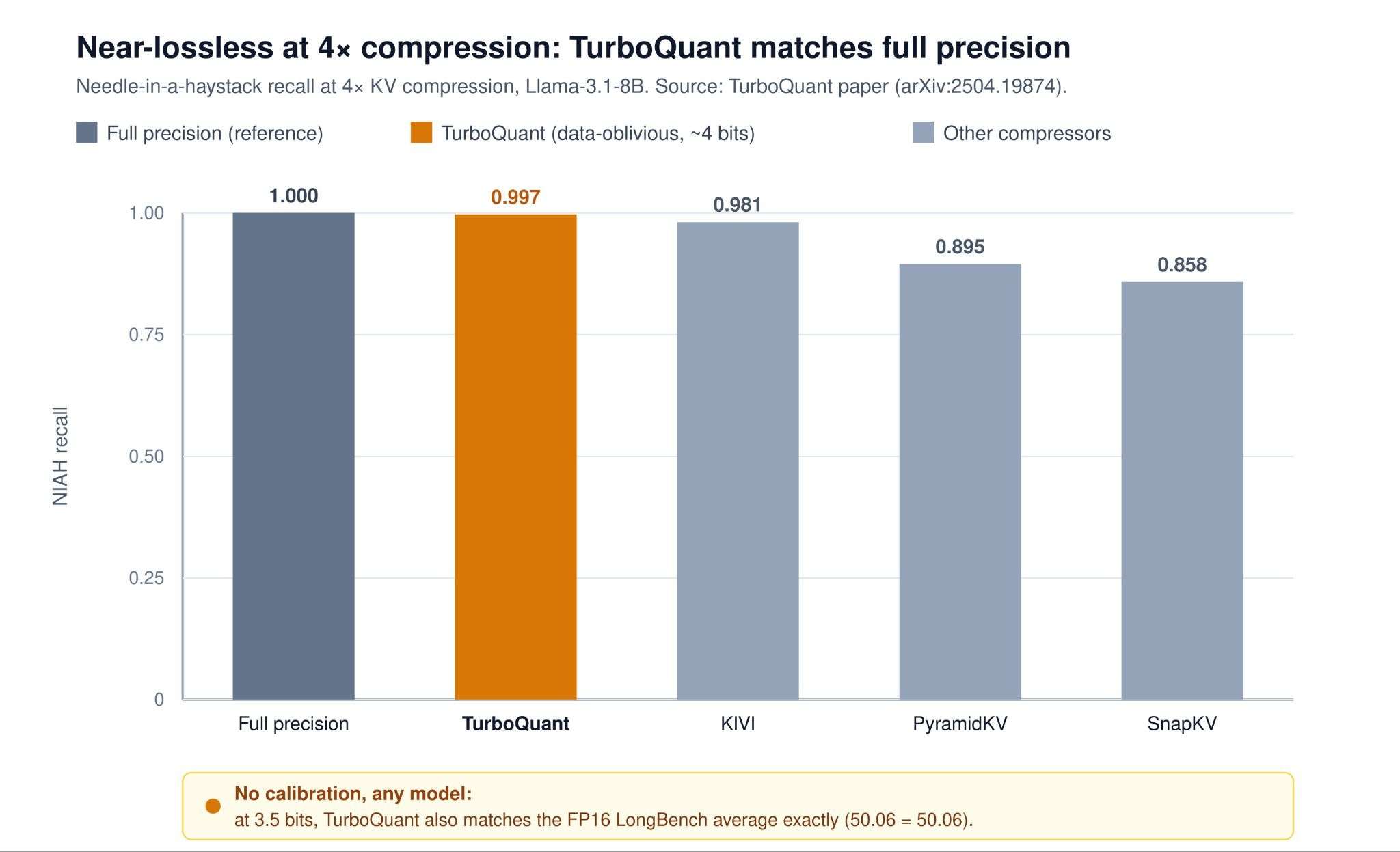
При работе с длинным контекстом в современных языковых моделях объем KV-кэша (Key-Value cache) часто превышает размер весов самой модели, создавая критическое узкое место в оперативной памяти. Для решения этой проблемы активно развиваются методы сжатия, среди которых выделяются три ключевых подхода: TurboQuant, OSCAR и EpiCache. Каждый из них предлагает свой способ оптимизации хранения данных, позволяя эффективно обрабатывать массивы токенов без существенной потери точности генерации.
TurboQuant фокусируется на квантовании кэша, снижая разрядность хранимых значений, что позволяет значительно сократить потребление памяти при сохранении производительности инференса. В свою очередь, OSCAR и EpiCache применяют стратегии динамического отбора и удаления менее значимых состояний кэша в процессе обработки последовательности. Эти методы позволяют системе «забывать» нерелевантную информацию, сохраняя при этом критически важные контекстные связи для длинных диалогов или анализа больших документов.
Технологии не являются прямыми конкурентами, а скорее дополняют друг друга в рамках архитектуры инференса. Использование комбинации квантования и интеллектуального прореживания кэша позволяет разработчикам запускать модели с контекстным окном в сотни тысяч токенов на менее мощном оборудовании. Оптимизация KV-кэша становится обязательным этапом при построении масштабируемых агентных систем, где требуется высокая скорость отклика и работа с объемными базами знаний в режиме реального времени.