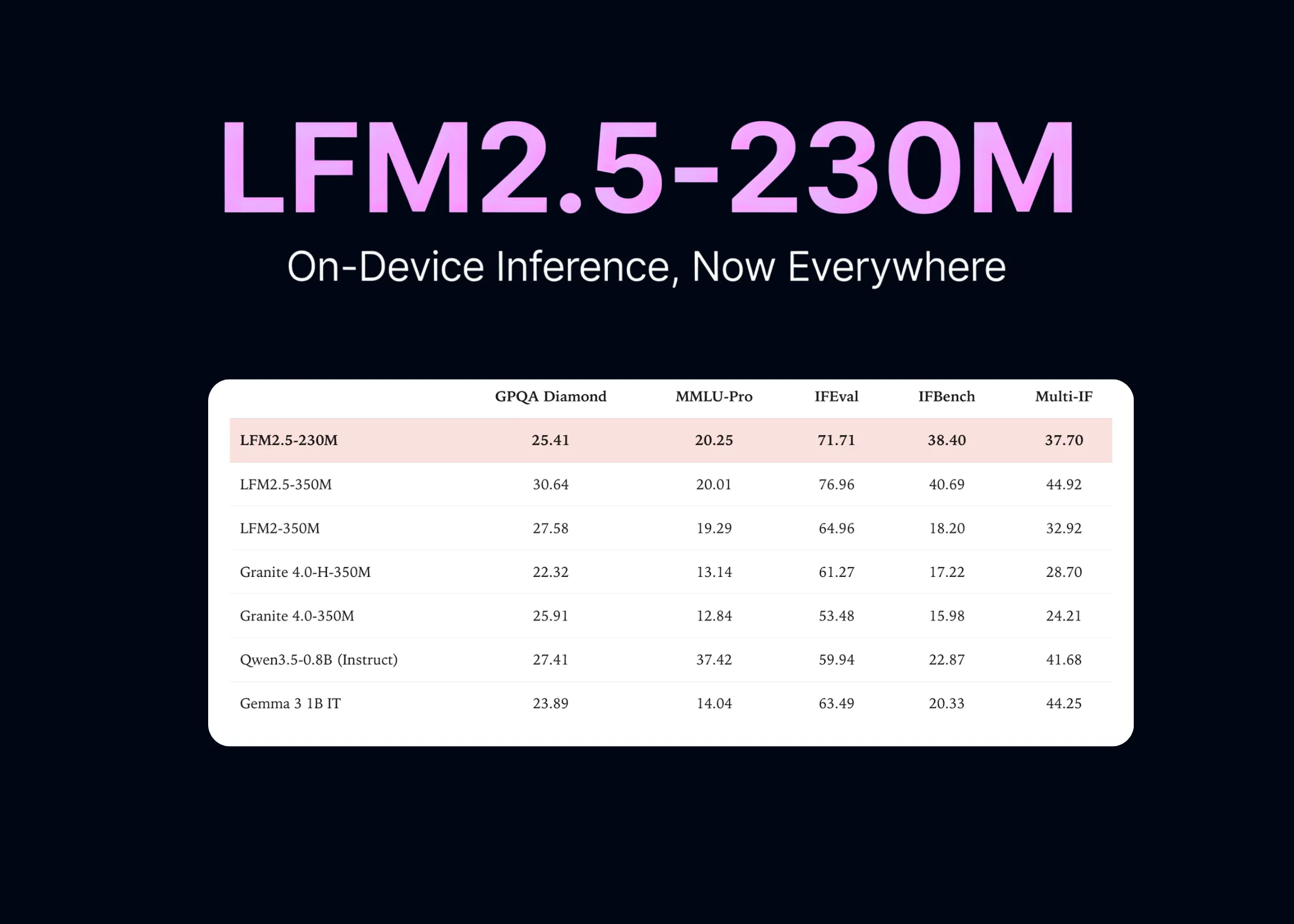
Компания Liquid AI представила LFM2.5-230M — свою самую компактную нейросеть с 230 млн параметров. Модель оптимизирована для работы на периферийных устройствах, демонстрируя высокую скорость генерации текста. Она поддерживает популярные фреймворки инференса, такие как llama.cpp и vLLM, и показывает превосходство над более крупными аналогами в задачах извлечения данных и выполнения инструкций.
Архитектура LFM2 обеспечивает эффективное использование ресурсов, что позволяет запускать модель даже на оборудовании с ограниченной производительностью, например, на Raspberry Pi 5. Разработчики сфокусировались на прикладных сценариях, где критически важны низкая задержка и работа без обращения к облачным серверам. Поддержка форматов ONNX и MLX упрощает интеграцию решения в существующие мобильные и встраиваемые системы.
В тестах на следование инструкциям модель обходит конкурентов в лице Qwen3.5-0.8B и Gemma 3 1B, несмотря на значительно меньшее количество параметров. Это делает LFM2.5-230M перспективным инструментом для создания локальных агентных систем, требующих быстрой обработки данных «на борту» устройства без передачи конфиденциальной информации во внешние API.
Ключевые факты
- Модель содержит 230 миллионов параметров и оптимизирована для работы на устройствах с ограниченными ресурсами.
- Скорость генерации достигает 213 токенов в секунду на смартфоне Samsung Galaxy S25 Ultra и 42 токенов в секунду на Raspberry Pi 5.
- Обеспечена нативная поддержка экосистемы инструментов: llama.cpp, MLX, vLLM, SGLang и ONNX.
- Архитектура LFM2 превосходит модели Qwen3.5-0.8B и Gemma 3 1B в задачах извлечения данных и точности следования инструкциям.