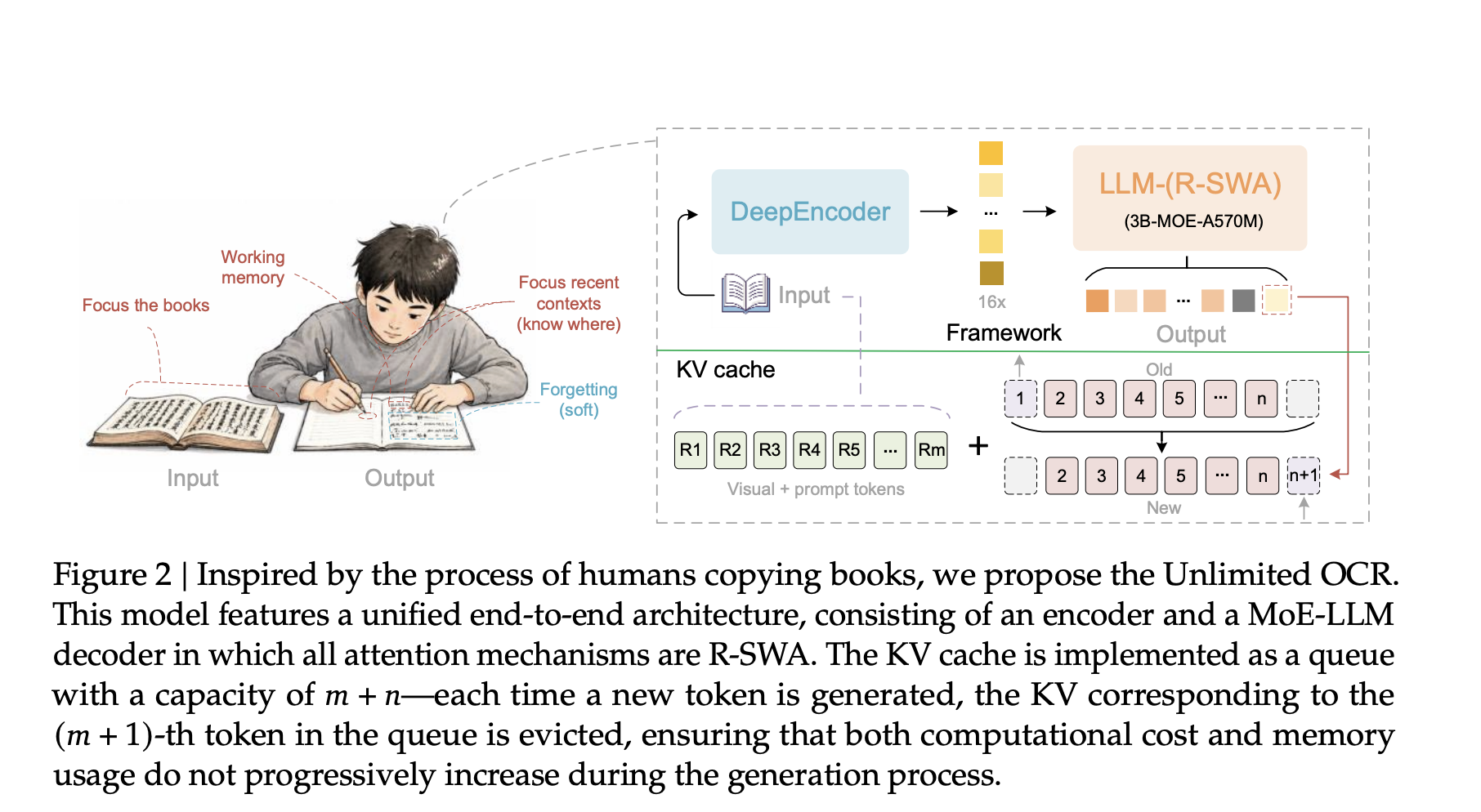
Baidu выпустила Unlimited OCR — специализированную MoE-модель с 3 млрд параметров, предназначенную для обработки многостраничных документов. Главная особенность архитектуры заключается в использовании механизма Reference Sliding Window Attention (R-SWA), который поддерживает постоянный размер KV-кэша. Это позволяет модели сохранять стабильную скорость работы и потребление памяти независимо от объема входных данных, значительно превосходя существующие аналоги.
Традиционные модели для распознавания текста часто сталкиваются с проблемой линейного роста задержек и потребления VRAM при увеличении количества страниц. Unlimited OCR решает эту задачу за счет оптимизации внимания, что делает её эффективным решением для задач анализа длинных документов в реальном времени. Модель демонстрирует высокую точность на специализированных бенчмарках, опережая текущие отраслевые стандарты.
Релиз модели под лицензией MIT открывает широкие возможности для интеграции в корпоративные системы обработки документов, где требуется высокая производительность при ограниченных вычислительных ресурсах. Использование архитектуры Mixture-of-Experts (MoE) позволяет модели сохранять компактность при сохранении глубокой способности к пониманию структуры сложных документов.
Ключевые факты
- Модель Unlimited OCR содержит 3 миллиарда параметров и использует архитектуру MoE.
- Механизм R-SWA обеспечивает фиксированный размер KV-кэша, предотвращая рост задержек при увеличении длины документа.
- Модель набрала 93,23 балла в бенчмарке OmniDocBench v1.5.
- Результат модели на 6,22 балла выше показателей DeepSeek OCR.
- Исходный код и веса модели доступны под лицензией MIT.