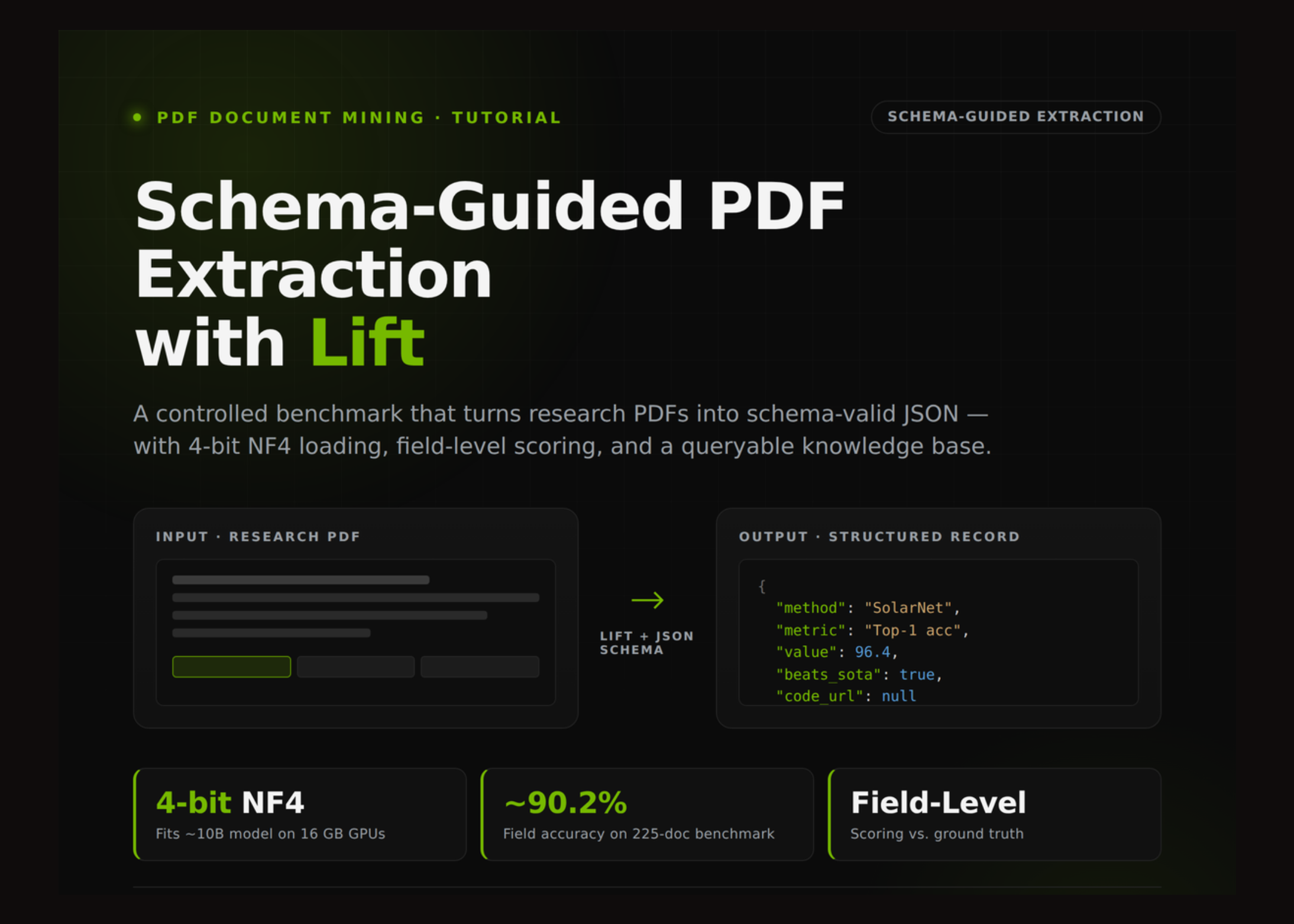
Разработан рабочий процесс для трансформации неструктурированных научных PDF-документов в структурированный JSON с использованием модели Lift. Решение фокусируется на контролируемой оценке качества извлечения данных, включая проверку полей на соответствие заданной схеме и сравнение результатов с эталонными значениями, что позволяет создавать надежные базы знаний для последующих запросов и аналитики.
В основе подхода лежит использование GPU-ускорения в среде Google Colab и квантование модели Lift до 4-битного формата NF4. Процесс включает генерацию синтетических отчетов с намеренно добавленными «шумовыми» данными для тестирования устойчивости алгоритма. Такой метод позволяет не просто извлекать текст, а проводить глубокую валидацию каждого извлеченного поля, минимизируя галлюцинации модели при работе с технической документацией.
Система ориентирована на создание воспроизводимых пайплайнов данных, где каждый этап извлечения поддается количественной оценке. Это критически важно для задач, требующих высокой точности при обработке больших массивов научной литературы, где ошибки в структурировании данных могут привести к искажению выводов в итоговых аналитических системах.
Ключевые факты
- Использование квантования 4-bit NF4 для оптимизации потребления ресурсов GPU при инференсе.
- Внедрение механизма schema-guided extraction для принудительного соответствия выходных данных заданной структуре.
- Реализация системы полевого скоринга (field-level evaluation) для сравнения извлеченных данных с ground truth.
- Создание queryable knowledge base — итогового хранилища, готового для выполнения структурированных запросов.
- Использование синтетических данных с дистракторами для верификации точности извлечения в условиях зашумленной информации.